实时渲染:基础架构与图形管线
前言
渲染管线是将三维场景转化为二维图像的函数,只需要给定三维对象、光源等等。三维物体的显示效果由材质属性、光源、纹理、采用的着色方程共同决定。
架构
渲染管线就像流水线一样,每一层级联,每个阶段完成特定的任务。每个管线任务是并行化运行的,而管线内部的阶段则是依赖于前一个阶段的输出。
首先,渲染管线可以粗略地分为四个主要的阶段——应用-几何处理-光栅化-像素处理。应用阶段通常由 CPU 来完成,主要任务有碰撞检测、全局加速算法、动画、物理模拟等等;集合处理阶段由 GPU 完成,处理线性变换、透视投影以及任何其他的几何操作;光栅化阶段通常将每三个顶点拼成一个三角形,然后找到三角形内的像素;像素处理阶段决定每个像素的颜色,也可以有模板测试、深度测试等抛弃像素的操作以及前后像素的混融操作。
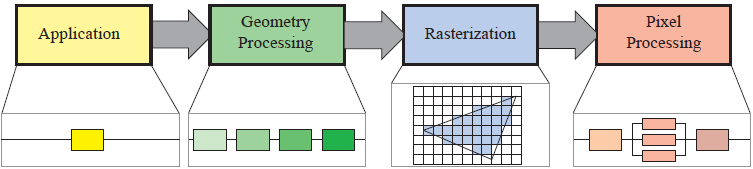
应用阶段
应用阶段控制将会控制整个渲染管线的进行方式,有大量的逻辑判断,通常由 CPU 来完成。主要工作是将数据组织好之后,推送到几何处理阶段,同时也会做碰撞检测,以及预先剔除等工作。
几何处理
几何处理阶段负责绝大多数的逐三角形和逐顶点操作。几何处理还可以细分为四个阶段:顶点着色、透视投影、裁切、屏幕映射。顶点着色有两大任务:计算顶点位置、计算后续可能需要的法线、纹理坐标等数据。也有一些应用会在 vertex shader 中计算着色,再在之后的阶段进行插值,达到节约性能的目的。
后续是三个可选几何处理操作。第一个可选阶段是细分。顶点可以用来描述点、线、三角形等,更重要的是,它可以用来描述曲面,曲面可以用一系列的顶点集合来表示。细分阶段又由三个处理阶段组成:hull shader、细分器、domain shader,用于生成更多的顶点集合,渲染更细腻的场景。然后是 geometry shader,GS 可以按照规则生成其它几何形状。用的较多的有粒子生成,对于每一个输入到 GS 粒子顶点,GS 将每顶点拓展为面向相机的长方形来实现粒子效果。最后是流输出(stream output)。在这个阶段,可以将 GPU 看做一个几何引擎,可以放弃将顶点推入后续阶段,输出数据到指定缓冲中。这样,数据可以被 CPU 或者其它 pass 使用。
只有位于齐次裁剪空间(canonical view volume,cvv)空间的图形才会被传输到光栅化阶段中,cvv 空间中的图元会被单位立方体所裁切。裁切阶段使用的是透视投影变换之后的齐次坐标,所以数值不可以直接在透视空间中进行线性插值。齐次坐标的第四个分量需要在光栅化阶段线性插值的时候进行透视校正。最后,执行透视除法,将齐次坐标转换为三维的标准设备坐标。
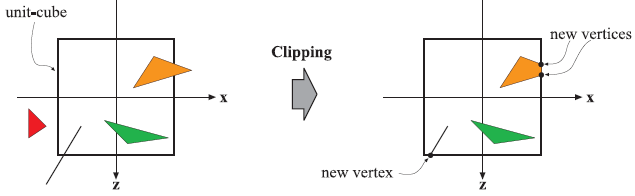
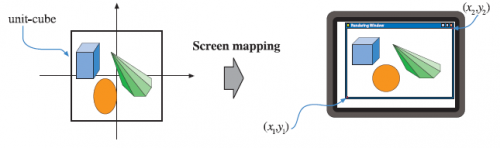
光栅化
光栅化阶段分为两个子阶段:图元装配和图元遍历。在图元装配阶段,差分、边缘方程以及其他三角形要用到的数据都会在这一阶段被计算。这些数据用于图元遍历,以及从几何处理阶段得到着色数据的插值。这一阶段使用的是固定的硬件来实现的,不可更改。当三角形覆盖到了像素的中心点,就会在像素位置为该三角形生成一个片元(fragment),寻找三角形内部的像素这一操作便被称为图元遍历。每个片元会用到三角形的三个顶点数据进行插值,这些数据包括所有几何阶段为每顶点生成的数据,以及片元的深度。实际上,透视空间的三角形不能直接用来做线性插值,还需要有透视校正的操作。
像素处理
像素处理阶段分为两个子阶段:像素着色与像素合并。所有逐像素着色的计算都在这个阶段进行。像素着色阶段主要进行光照计算以及纹理采样。素的信息被存储在 color buffer 中,像素合并的工作就是将当前阶段生成的片元颜色和 buffer 中已有颜色的合并。像素合并又可以成为 ROP(raster operations pipeline,光栅化操作管线)。像素合并阶段也负责消隐操作,主要通过 z-buffer 进行,但 z-buffer 对每个像素只保存了一个像素值,半透明问题的处理是 z-buffer 的弱项。
像素合并还有四个可配置的操作。首先,可以用 alpha 通道来存储信息用于舍弃片元,在较老的 API 里,这个操作叫做 alpha test,是一个专门的测试,现代图形 API 中,像素着色器中可以直接添加 discard 操作来弃置片元;然后是 scissor test,它可以指定一个矩形,位于矩形之外的片元都会被舍弃;接下来有 stencil buffer 来存储渲染图元的位置信息,通常每个像素占用 8 个 bit,记录的绘制信息可以在之后渲染到 color buffer 和 z-buffer 时加以利用。最后的操作是混融操作,提供了将当前计算片元的颜色值与已存储的颜色值按比例混合的能力,可以用于半透明计算。
双缓冲结构
当所有的操作都结束之后,像素值被写到 frame buffer 上,之后会被展示到屏幕中。为了避免用户看到光栅化的过程,通常会使用双缓冲结构。下一帧的图像会渲染到 back buffer 中,当渲染完毕,进行交换操作,back buffer 转换为 front buffer,展示到屏幕上。现代的交换操作会等待 GPU 的垂直同步操作,由 GPU 告知能否进行交换,防止数据冲突错误。
数据并行架构
并行架构有许多,它们的共同目的就是避免指令流水线的停顿。现在 CPU 进过特定的优化,专门用来处理复杂的数据结构以及庞大的代码;所以 CPU 虽然有多个核,除了极少数 SIMD 向量处理之外,基本各个核都单独以串行方式运行。为了降低延迟效应,CPU 都会配备快速缓存,以及一些特殊的软件技巧比如分支预测、指令重排列、寄存器重命名、缓存数据预取等等。
GPU 则采取了另一种不同的方法。GPU 部署了大量名为“着色器核心”的小处理器,通常数以千计;GPU 是一种流处理器,按批次处理组织好的相同性质的数据集。由于数据的相似性,GPU 才能拥有大规模数据计算的能力。不仅如此,GPU 要求不同数据的处理之间越独立越好,即不依赖相邻调用的数据、相邻调用不会对同一块内存进行写操作,处理器之间不会因为互相等待数据而造成流水线停滞。
GPU 的优化方向是吞吐量(throughput),也就是说尽可能提高单位时间内能够处理的数据量。由于 GPU 分配给每个处理器的缓存和控制逻辑都少得多,每个着色器核心的 latency 要比 CPU 处理器长得多。比如纹理采样,纹理数据不可能缓存到所有处理器的 local memory 中,而一次 memory fetch 操作需要上千个时钟周期,这会造成处理器的停滞。
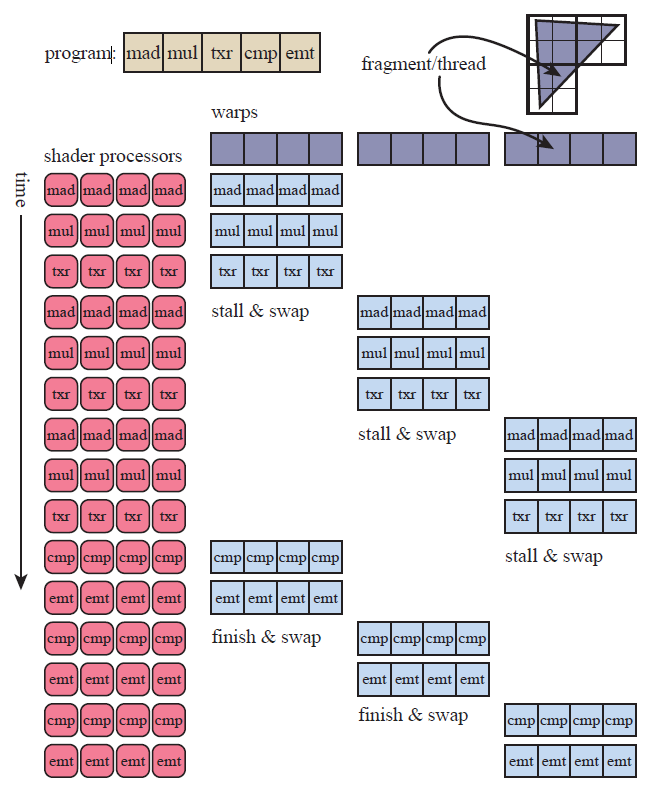
为了处理 latency 问题,GPU 为每一个线程都分配了少量的寄存器。这样,当 memory fetch 操作发生时,着色器处理器会允许切换执行其他的着色器线程,拥有大量寄存器的线程组切换是非常快的。当第二组线程遇到阻塞时,又可以快速切换到第三组线程,以此类推。依靠 GPU 强大的线程快速切换能力,总数据处理时间就可以极大降低。
在上述的架构中,latency 被 GPU 的快速切换能力给隐藏了(latency hiden)。更进一步,现代 GPU 拥有 SIMD 指令集,每个指令可以对每组数据做同样的运算操作(single instruction,multiple data),处理数据按组进行,硬件的使用权在组与组之间切换,避免单独线程的切换成本。这样,一定数量的线程共同操作的基本单位就称为 wrap,通常包含 8 到 64 个线程。需要注意的是,GPU 中的线程与 CPU 有所不同。GPU 线程只需要少量内存空间作为数据输入和一定数量的寄存器来提供执行线程。
着色器程序的结构会严重影响运算效率。主要因素是每个线程的寄存器数量是有限的,每个线程需要的寄存器数量越多,那么能够驻留在 GPU 中的 wrap 就会越少。如果 wrap 的数量太少,切换运行的时间可能无法覆盖阻塞时间,仍然会导致效率降低。衡量 wrap 数量的指标称为“占有率”(occupancy),等于就绪态的 wrap 数量除以总 wrap 数量。较高的占有率意味着有许多的 wrap 等待切换,处理器处于空闲状态的可能性大大降低;较低的占有率往往会造成性能损失。最后,memory fetch 的数量影响需要被 latency hiden 的时间总长度,从而影响最终性能。
另一个影响运算效率的因素是动态分支,通常由 if 语句和循环结构产生。在 GPU 中,如果 wrap 的所有线程都运行同一个分支,wrap 就不需要关注其它分支的情况;然而,即使 wrap 中只有一个线程处于另一分支中,wrap 也需要运行完这一个分支,再统一运行另一个分支。这种问题成为“线程发散”(thread divergence)。
简化的着色器运行模型:
可编程着色器
现代着色器使用的是统一的着色器设计模型:顶点、几何、细分等着色器使用的是共同的编程模型,使用着同样的指令集结构(instruction set architexture,ISA)。这样,可以保证不同着色器组合的负载平衡,防止处理器空闲。比如,远处的复杂网格更依赖顶点着色器,像素着色器会比较空闲;近处的简单网格则更依赖像素着色器。
调用图形 API 使用特定着色器绘制一组图形的操作称为 draw call。每个可编程着色器都有两种输入:uniform 和 varying。uniform 表示输入数据在整个 draw call 过程都保持不变,可以由 host 端在不同 draw call 之间修改;varying 表示数据来源于三角形顶点或者光栅化。需要注意的是,纹理是特殊的 uniform 输入。
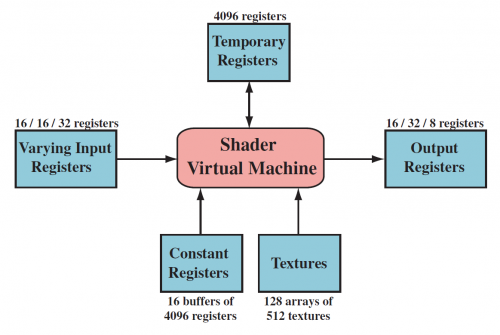
图示为 SM4.0 下着色器虚拟机架构和寄存器布局。用于 uniform 输入的常量寄存器数量比 varying 输入的数量要大得多。因为 varying 输入存储的是单个顶点或像素的数据,分配到每个顶点或像素的寄存器就非常少了;而 uniform 输入数据只存储一次,可以在整个 draw call 阶段重复使用。虚拟机中还有通用的临时寄存器,用于 scratch space 中,存储运算得到的临时数据。
参考:Real-Time Rendering, 4th Edition